Dreaming is the process of maximizing some internal or output feature of a neural network by iteratively tweaking the input to the network. The most well-known example is DeepDream [1]. Besides making pretty images, dreaming is useful for interpreting the purpose of the internal components of a neural network [2]–[4]. To our knowledge, Dreaming has previously only been applied to vision models because the input space to a vision model is approximately continuous and algorithms like gradient descent work well. For language models, the input space is discrete and very different algorithms are needed. Extending work in the adversarial attacks literature [5], in the paper, we introduce the Evolutionary Prompt Optimization (EPO) algorithm for dreaming with language models.
On this page, we demonstrate running the EPO algorithm for a neuron in Phi-2. There is also a Colab notebook version of this page available.
Installation and setup
Click to view install and imports
First, we install necessary dependencies and install the dreamy library:
In this section, we run the EPO algorithm. In order to use EPO, we first need to define an objective function. The objective function is responsible for executing a model forward pass and capturing whatever optimization “target” that we want to maximize. The API for defining an objective function is:
accept an arbitrary set of arguments that will be passed on to the model.
return a dictionary with a minimum of two keys:
target: a target scalar that will be maximized.
logits: the token probabilities output by the model. These are used to calculate cross-entropy/fluency.
other keys in the dictionary can optionally be used to pass info to a per-iteration monitoring callback. For more details, see the docstring of the epo function.
Here, we are going to define an objective that maximizes the activation of a chosen neuron in Phi-2. We use a hook on the MLP layer to capture the activations of the chosen neuron. We maximize the activation only on the last token of the sequence.
beginning step 299, current pareto frontier prompts:
penalty=0.01 xentropy=8.09 target=4.56 ' study found another pattern by told-Mike Heyya, making[ the]'
penalty=0.16 xentropy=7.59 target=4.48 ' study found another pattern by told-Mike Heyde, making[ the]'
penalty=0.41 xentropy=5.16 target=3.50 ' study encountered another example of similar-unmatched pairs, with[ the]'
penalty=0.98 xentropy=4.43 target=2.80 ' study found another pattern of similar-unmatched pairs, with[ the]'
penalty=2.25 xentropy=4.43 target=2.80 ' study found another pattern of similar-unmatched pairs, with[ the]'
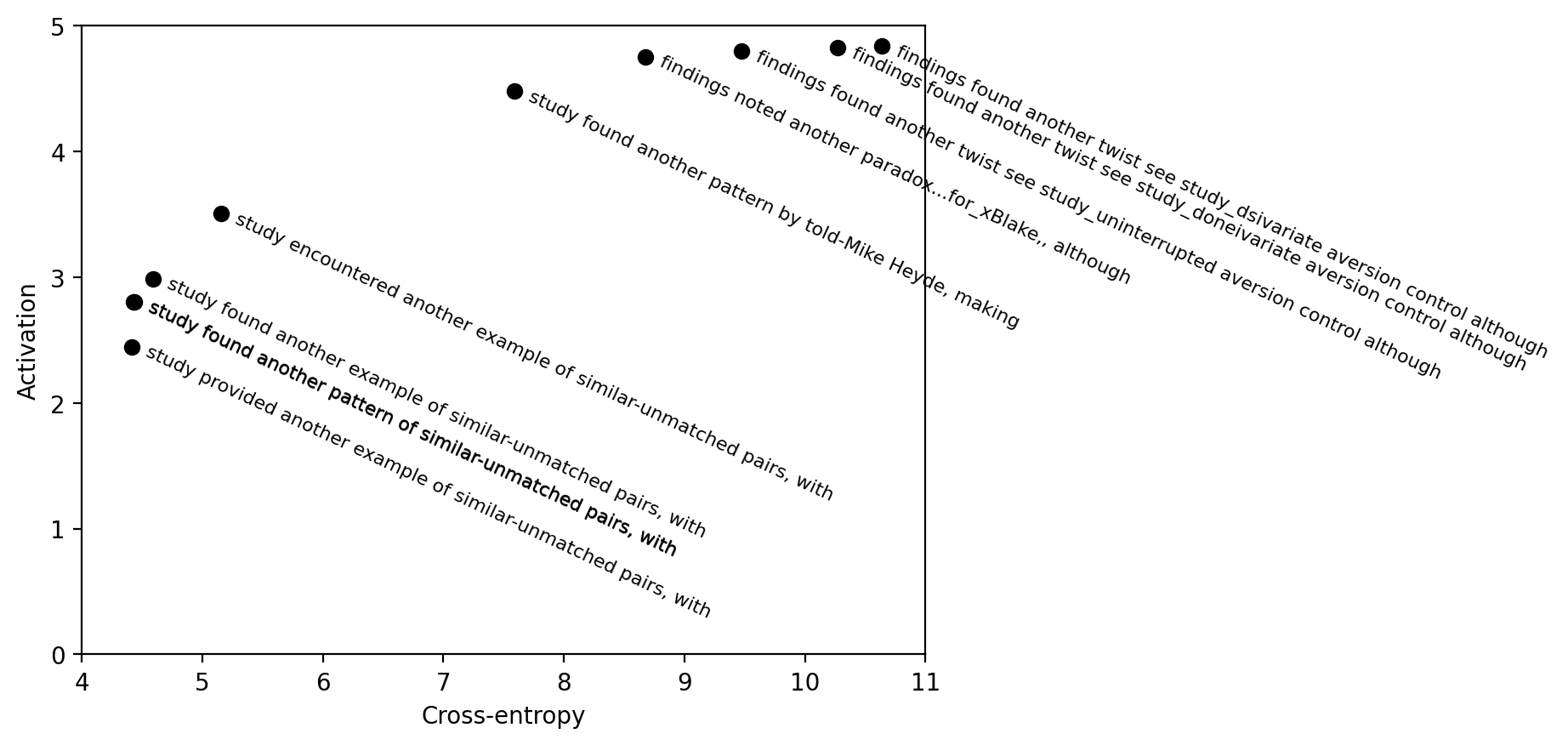
The Pareto frontier
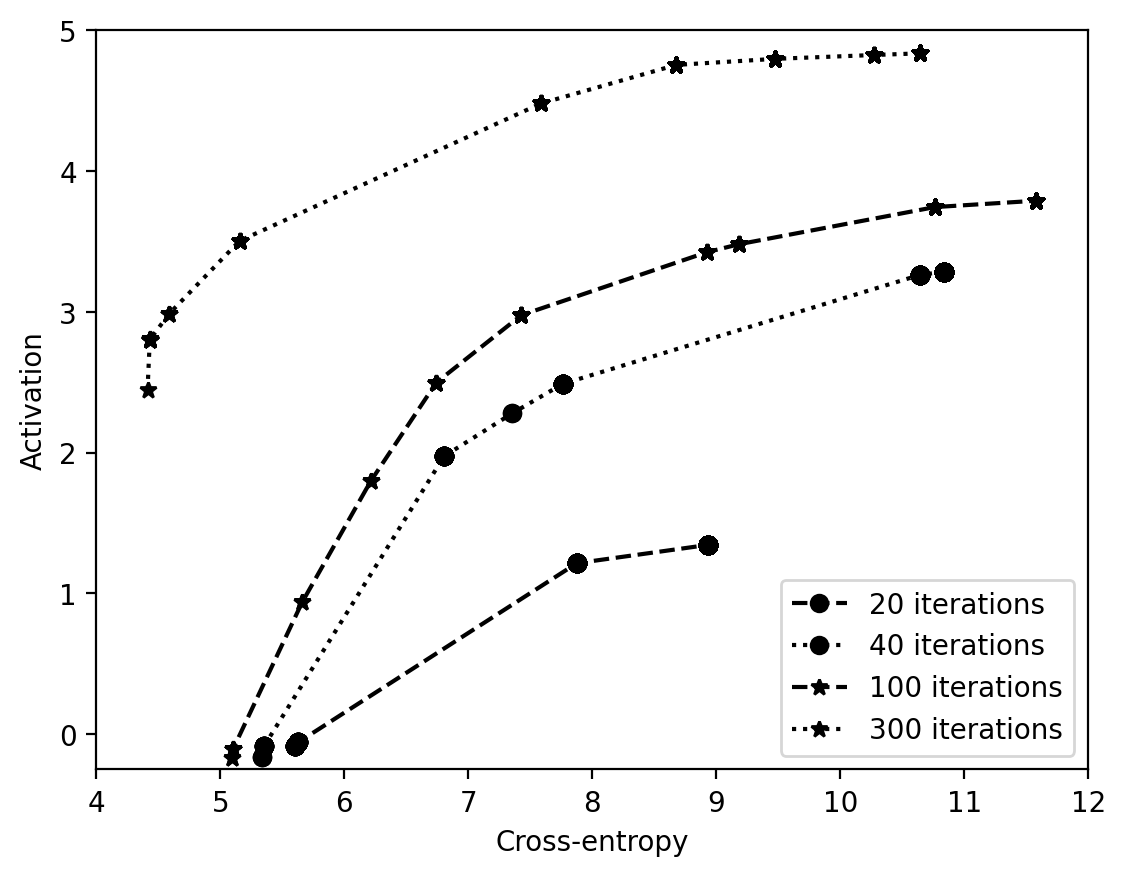
To visualize the results of this EPO run, we first plot the Pareto frontier of cross-entropy against activation.
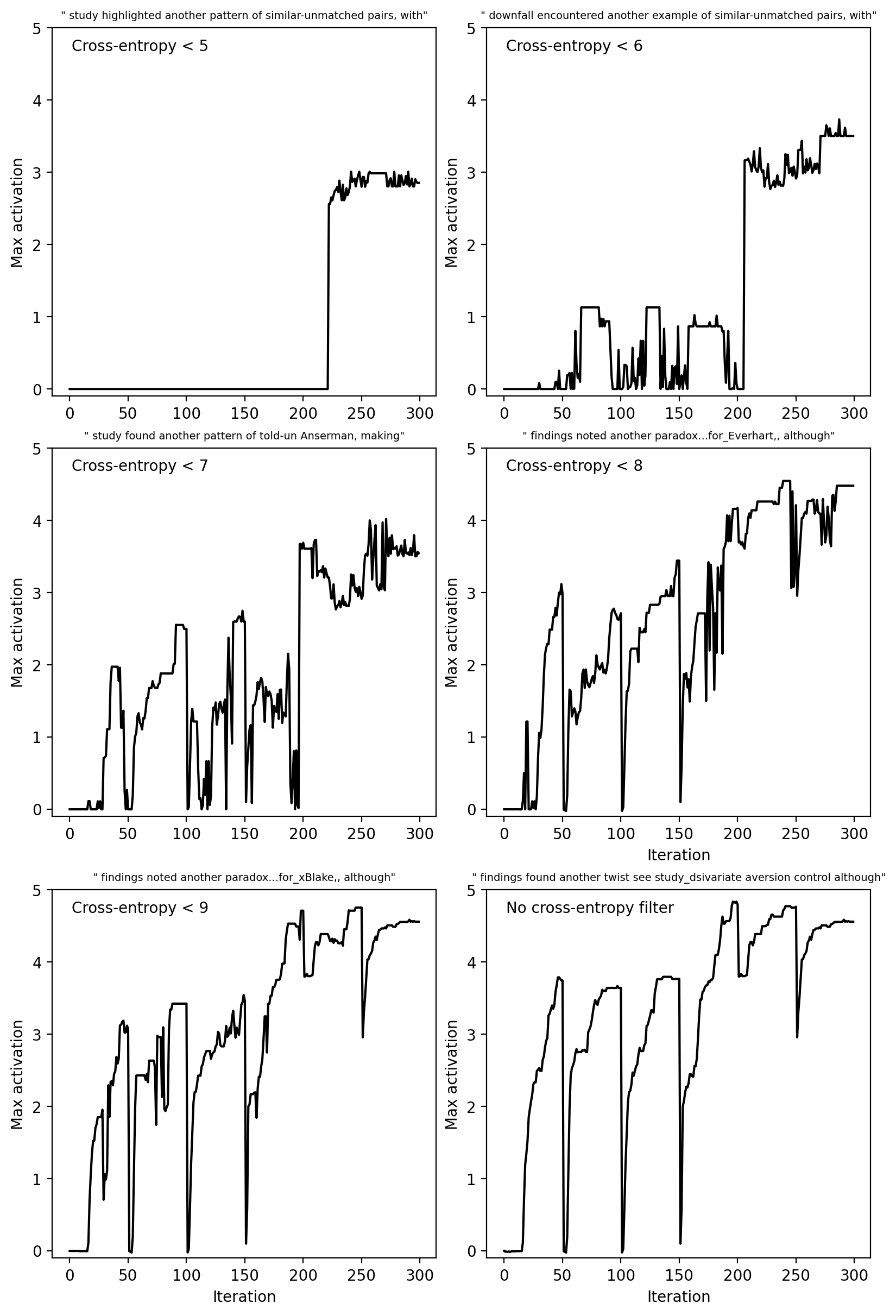
An alternative way of visualizing the results of an EPO run is to consider only the subset of prompts with cross-entropy below some fixed threshold. Below, we plot the maximum activation across the 300 iterations of EPO for six different thresholds. The title of each plot shows the maximum activating prompt under the cross-entropy threshold across all iterations. The sharp drops every 50 iterations are from restarts. Sometimes there’s a plateau before the restart and other times progress is continuing. This suggests that a more adaptive restarting algorithm would perform better.
The visualizations below show the sensitivity to each token in the prompts. We first filter to the 32 “best” alternative tokens based on backpropagated token gradients. Then, amongst those 32 tokens, we calculate two sensitivities:
the drop in activation from swapping the token to the next highest activation alternative token. In the visualization, we show this in the height of the token bars.
the drop in activation from swapping the token to the lowest activation alternative token. In the visualization, we show this with the color of the tokens. Darker reds indicate a larger drop in activation.
The visualizations are interactive. Hover over each token to see a tooltip with the top-3 highest activation alternative tokens and the single lowest alternative token.
We show attribution visualizations for each prompt on the Pareto frontier. For all the prompts, swapping the last token can reduce the neuron activation to zero. Swapping other token can reduces the activation much less. The comma in the second-to-last position is also important and often has no viable substitute which is indicated by its tall bar.
for i inrange(len(ordering)): _, viz_html = resample_viz( model, tokenizer, runner, torch.tensor(pareto.ids[ordering[i]]).to(model.device), target_name="L8.N1 activation", ) display(HTML(viz_html))
C. Olah, A. Mordvintsev, and L. Schubert, “Feature visualization,”Distill, 2017, doi: 10.23915/distill.00007.
[4]
J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, and H. Lipson, “Understanding neural networks through deep visualization.” 2015. Available: https://arxiv.org/abs/1506.06579
[5]
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models.” 2023. Available: https://arxiv.org/abs/2307.15043
Citation
BibTeX citation:
@online{thompson2024,
author = {Thompson, T. Ben and Straznickas, Zygimantas and Sklar,
Michael},
title = {Fluent Dreaming for Language Models},
date = {2024-01-23},
url = {https://confirmlabs.org/posts/dreamy.html},
langid = {en}
}